Everything you need to know to understand Serverless
🎓 What is it?
Serverless computing is a new architecture pattern allowing developers to deploy highly-scalable code to be run on demand, often as functions.

⌛ The past
Software is written to run on a computer. That much is obvious. The question of where that computer is, or who owns that computer is not as immediately obvious.
In the past, software run on servers that you (or your organization) owned. That model, known as “on-premise”, meant that you were in charge of maintenance of that machine, administrating the operating system, and managing the necessary resources (storage, networking, security) for that server to do its job.
Throughout the 90s, server companies began abstracting the physical management aspects of running software online. Instead of implementing storage redundancy and ensuring high availability for your machines, you could rent one of Rackspace’s machines, focus on getting your code up and running, and leave the “operations” work to the people who are good at it.
What we know today as “cloud computing” emerged as a variant of this idea in the late 2000s. Instead of renting an entire dedicated server for your software, cloud providers used virtualization to segment a larger physical server into smaller portions for use by developers.
To accompany the massive amount of software running in the cloud, cloud providers likeAmazon Web Services (AWS) and Google Cloud have continued to abstract services out into easier-to-use products. Instead of managing your own physical storage, you can useAWS S3 (Simple Storage Service) to store and retrieve your data. Instead of managing your own reverse proxy to distribute workload between your servers, you can spin up an automatic load balancer with Google Cloud’s Load Balancing product.
📌 Right now
If everything runs on the cloud, cloud providers naturally have a ton of server power at their disposal. Virtualization allowing them to give small chunks of computing power out to various companies and organizations, but there’s still bound to be bits and pieces of computing power that isn’t being used.
Serverless takes that extra computing power and makes it available at the function level. This means that instead of running an entire web application on the cloud, you’re deploying small parts of that application — an API endpoint, or an authentication function.
Serverless often is talked about in terms of functions. In that way, it corresponds neatly with many of the architectural ideas around functional programming: that programs should be composed of smaller (often immutable) functions.
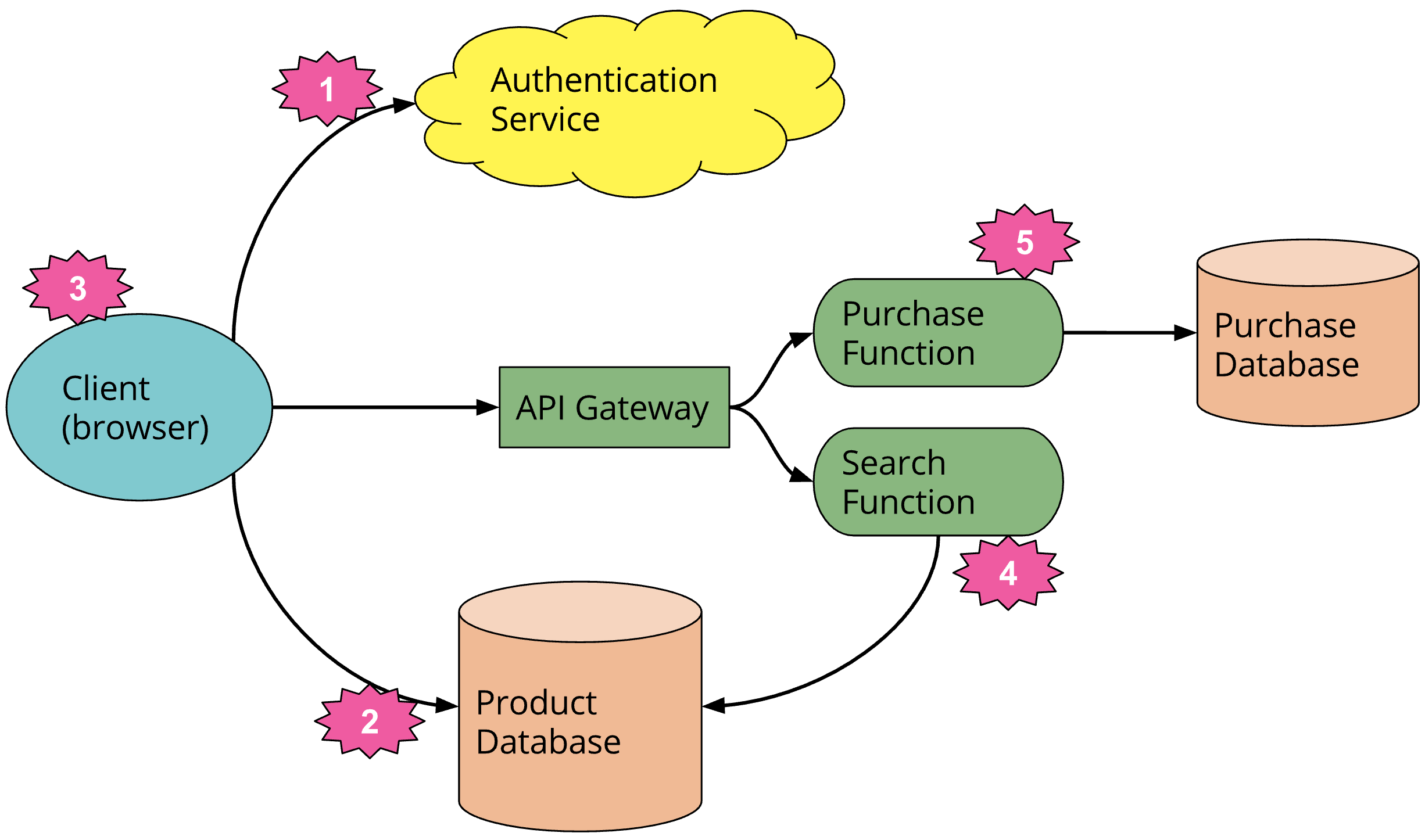
Image courtesy of “Serverless Architectures” by Martin Fowler.
Because serverless functions are tightly bound, often just a single JavaScript function or file, they’re cheap to run. Instead of needing to keep an entire (virtualized or physical) active 24/7 for the purposes of one application, serverless functions can essentially run on any server in AWS or Azure’s computing farm that has available computing power.
This means that serverless function executions are quite cheap, and for certain kind of applications, such as APIs (especially highly cacheable ones), it’s an incredible way to save money. By building on serverless, Troy Hunt’s Have I Been Pwned API cost $7.40 in June 2018 to serve 54 million searches.
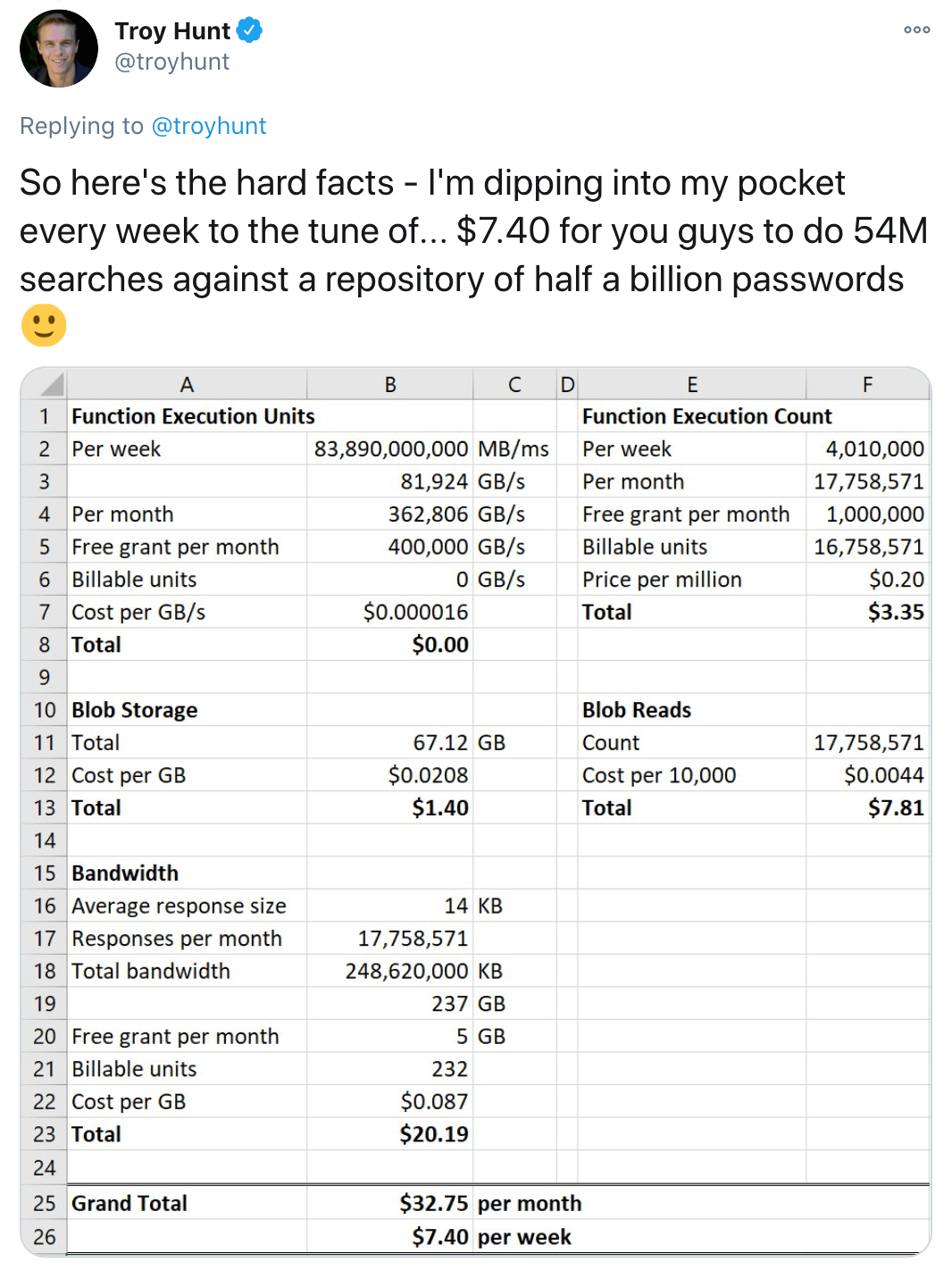
👶 Where to start
AWS Lambda is the most popular platform for deploying serverless functions. It supports a number of languages, like JavaScript, Ruby and Python.
Most serverless functions are accessed via HTTP (though not all!), so learning the basics of HTTP can make it easier to wrap your head around how to build your first serverless functions. Here’s what you should know:
- the difference between
GETandPOSTrequests - how to correctly set HTTP status codes
- sending and requesting information with request bodies and parameters
The Serverless framework makes it easy to deploy functions to a number of providers and has a bustling community.
James Quick covered serverless at a high level and looked at how to deploy your first function on the popular YouTube channel Traversy Media.
📈 What’s next?
One of the defining characteristics around serverless is the vast amount of opportunity to improve both developer experience and performance characteristics. Simply put: there is a lot still to be done in serverless.
On the developer experience front, many providers and tools are building higher level abstractions to make it easier for developers to just ship code. The aforementioned Serverless framework allows you to deploy your code to production-ready API endpoints in minutes, and Netlify is making it easy to take your serverless functions and deploy them alongside your front-end applications.
Platforms like Cloudflare Workers* are finding that by picking the right architectural constraints can have vast implications for performance—by building directly on Google’s V8 JavaScript engine instead of Node, Workers functions start instantly and execute on an “edge” server, located geographically close to the user. This means that your functions execute and return data to your users closer to 100ms rather than 10s.
* Disclaimer: I work at Cloudflare as the developer advocate for Workers.
The other frontier in serverless worth exploring right now is how it can be used to build improvements on past cloud abstractions. Storage remains a big in-progress problem, with tools like Aurora Serverless and Cloudflare Durable Objects innovating on what it means to have highly-available and scalable storage available in your serverless functions. Security, whether basic authorization in an API or working with identity management platforms like Auth0 can drastically simplify your application using serverless, without porting everything to it.